Firstly, we need to clarify that HADR in SAP ASE speak, is the SAP ASE feature-set name for a HA or DR setup consisting of 2 SAP ASE database instances with a defined replication mode.
The pair can be either for HA or DR, but rarely both, due to the problem of latency.
The problem of latency is inverse to the solution of DR. The further away your second datacentre, the better, from a DR perspective.
Conversely, the worse your latency will become, meaning it can only seriously be used for DR, and not for HA.
If you can find a sweet spot between distance (better for DR) and latency (better for HA), then you would have a HADR setup. But this is unlikely.
As of ASE 16 SP03, an additional DR node is supported to be incorporated into a HADR pair of ASE database instances.
This produces a 3 node setup, with 2 nodes forming a pair (designed to be for HA), then a remote 3rd node (designed for DR).
The reason you may consider such a setup is to provide HA between the two nodes, maybe within an existing datacentre, then DR is provided by a remote 3rd node.
Since the two nodes within the HA pair would likely have low latency, they would have one replication mode (e.g synchronous replication) keeping the data better protected, with the replication mode to the third database being asynchronous, for higher latency scenarios, but less protected data.
In the scenarios and descriptions below, we are highlighting the possibility of running a two node HADR pair plus DR node in public cloud using a paired region:
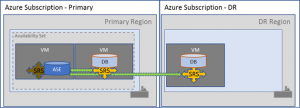
Whilst an SAP application layer is also supported on the 3 node setup, there are complications that should be understood prior to implementation.
These complications will drive up both cost of implementation and also administrative overhead, so you should ensure that you fully understand how the setup will work before embarking on this solution.
Setup Process:
We will briefly describe the process for setting up the 3 nodes.
In this setup we will use the remote, co-located replication server setup, whereby the SAP SRS (replication server) is installed onto the same servers as the ASE database instances.
1, Install primary ASE database instance.
2, Install Data Movement (DM) component into the binary software installation of the primary ASE database instance.
3, Install secondary ASE database instance.
4, Install Data Movement (DM) component into the binary software installation of the secondary ASE database instance.
5, Run the setuphadr utility to configure the replication between primary and secondary.
This step involves the materialisation of the master and <SID> databases. The master database materialisation is automatic, the <SID> database is manual and requires dump & load.
Therefore, if you have a large <SID> database, then materialisation can take a while.
6, Install tertiary ASE database instance.
7, Install Data Movement (DM) component into the binary software installation of the tertiary ASE database instance.
8, Run the setuphadr utility to configure the tertiary ASE instance as a DR node.
This step involves the materialisation of the master and <SID> databases. The master database materialisation is automatic, the <SID> database is manual and requires dump & load.
Therefore, if you have a large <SID> database, then materialisation can take a while.
In the above, you can adjust the replication mode between primary and secondary, depending on your latency.
In Public cloud (Microsoft Azure), we found that the latency between paired regions was perfectly fine for asynchronous replication mode.
This also permitted the RPO to be met, so we actually went asynchronous all the way through.
POINT 1:
Based on the above, we have our first point to make.
When doing the dump & load for the tertiary database, both master and <SID> databases are taken from the primary database, which in most cases will be in a different datacentre, so materialisation of a large <SID> database will take longer than the secondary database materialisation timings.
You will need to develop a process for quickly getting the dump across the network to the tertiary database node (before the transaction log fills up on the primary).
Developing this fast materialisation process is crucial to the operation of the 3 node setup, since you will be doing this step a lot.
Operational Process:
We now have a 3 node setup, with replication happily pushing primary database transactions from primary (they go from the Replication Agent within the primary ASE instance), to the SRS on the secondary ASE node.
The SRS on the secondary instance then pushes the transactions into the secondary ASE instance databases (master & <SID>) and also to the SRS on the tertiary ASE database instance.
While this is working, you can see the usual SRS output by connecting into the SRS DR Agent on the secondary node and issuing the “sap_status path” command.
The usual monitoring functions exist for monitoring the 3 ASE nodes. You can use the DBACockpit (DB02) in a Netweaver ABAP stack, the ASE Fault Manager or manually at the command line.
One of the critical processes with an ASE HADR setup, is the flow of transactions from primary. You will be constantly engaged trying to prevent the backlog of transactions, which could cause primary to halt database commits until transaction log space is freed.
By correctly sizing the whole chain (primary, secondary and tertiary transaction logs) plus sizing the inbound queues of the SRS, you should have little work to do on a daily basis.

POINT 2:
It’s not the daily monitoring that will impact, but the exceptional change scenarios.
As an example, all 3 ASE database instances should have the same database device sizes, transaction log sizes and configuration settings.
Remembering to increase the device, database, transaction log, queue on each of them can be arduous and mistakes can be made.
Putting a solid change process around the database and SRS is very important to avoid primary database outages.
Since all 3 databases are independent, you can’t rely on auto-growby to grow the devices and databases in sync. So you may need to consider manually increasing the device and database sizes.
Failover Process:
During a failover, the team need to be trained in the scenario of recovery of the data to whichever database server node is active/available/healthy.
The exact scenario training could be difficult as it may involve public cloud, in which case it may not be possible to accurately simulate.
For the 3 node SAP ASE HADR + DR node, the failure scenario that you experience could make a big difference to you overall recovery time.
When we mention recovery time, we are not just talking about RPO/RTO for getting production systems working, we are talking about the time to actually recover the service to a protected state.
For example, recovery of the production database to a point where it is once again adequately protected from failure through database replication.
Loss of the primary database in a 3 node setup, means that the secondary node is the choice to become primary.
In this scenario, the secondary SRS is no longer used. Instead the SRS on the DR node would be configured to be the recipient of transactions from the Replication Agent of the secondary ASE.
If done quickly enough, then re-materialisation of the tertiary database can be avoided as both secondary and tertiary should have the same point-in-time.
In practice however, you will find more often than not, that you are just re-materialising the DR node from the secondary.
In some cases, you may decide not to both until the original primary is back in action. The effort is just too much.
Loss of the secondary database in a 3 node setup, means that the primary becomes instantly unprotected!
Both the secondary node and the tertiary node will drift out of sync.
In this scenario, you will more than likely find that you will be pushed for time and need to teardown the replication on the primary database to prevent the primary transaction lo filling.
Loss of the tertiary database in a 3 node setup, means that you no longer have DR protection for your data!
The transaction log on the primary will start to fill because secondary SRS will be unable to commit transactions in the queue to the tertiary database.
In this scenario, you will more than likely find that you will be pushed for time and need to re-materialise the DR database from the primary.
Time will be of the essence, because you will need transaction log space available in the primary database and queue space in the SRS, for the time to perform the re-materialsation.
POINT 3:
Sizing of the production transaction log size is crucial.
The same size is needed on the secondary and tertiary databases (to allow materialisation (dump & load) to work.
The SRS queue size also needs to be a hefty size (bigger than the transaction log size) to accommodate the transactions from the transaction log.
The primary transaction log size is no longer now just about daily database transactional throughput, but is also intertwined with the requirement for the time it takes to dmp & load the DB across the network to the DR node (slowest link in the chain).
Plus, on top of the above sizings, you should accommodate some additional buffer space for added delays, troubleshooting, decision making.
You should understand your dump & load timings intricately to be able to understand your actual time to return production to a protected state. This will help you decide which is the best route to that state.
Maintenance Process:
Patching a two node ASE HADR setup, is fairly simple and doesn’t take too much effort in planning.
Patching a three node setup (HADR + DR node), involves a little more thought due to the complex way you are recommended to patch.
The basics of the process are that you should be patching the inactive portions of the HADR + DR setup.
Therefore, you end up partially patching the ASE binary stack, leaving the currently active primary SRS (on the secondary node) until last.
As well patching the ASE binaries, you will also have to patch the SAP Hostagent on each of the three nodes. Especially since the Hostagent is used to perform the ASE patching process.
Since there is also a SAP instance agent present on each database node, you will also need to patch the SAP Kernel (SAPEXE part only) on each database node.

POINT 4:
Database patching & maintenance effort increases with each node added. Since the secondary and DR nodes have a shared nothing architecture, you patch specific items more than once across the three nodes.
Summary:
The complexity of managing a two node SAP ASE HADR pair plus DR node should not be underestimated.
You can gain the ability to have HA and DR, especially in a public cloud scenario, but you will pay a heavy price in overhead from maintenance and potentially lose time during a real DR due to the complexity.
It really does depend on how rigid you can be at defining your failover processes and most importantly, testing them.
Carefully consider the cost of HA and DR, versus just DR (using a two node HADR setup with the same asynchronous replication mode).
Do you really need HA? Is your latency small enough to permit a small amount of time running across regions (in public cloud)?
